UPDATE: the paper got accepted at SOCIALCOM2012 and the source code and data sets are online especially the source code of the graphity server software is now online!
UPDATE II: Download the paper (11 Pages from Social Com 2012 with Co Authors: Thomas Gottron, Jonas Kunze, Ansgar Scherp and Steffen Staab) and the slides
I already said that my first research results have been submitted to SIGMOD conference to the social networks and graph databases track. Time to sum up the results and blog about them. you can find a demo of the system here
I created a data model to make retrieval of social news feeds in social networks very efficient. It is able to dynamically retrieve more than 10’000 temporal ordered news feeds per second in social networks with millions of users like Facebook and Twitter by using graph data bases (like neo4j)
In order to achieve this I had several points in mind:
- I wanted to use a graph data base to store the social network data as the core technology. As anyone can guess my choice was neo4j which turned out to be a very good idea as the technology is robust and the guys in sweeden gave me a great support.
- I wanted to make retrieval of a users news stream only depend on the number of items that are to be displayed in the news stream. E.g. fetching a news feed should not depend on the number of nodes in the network or the number of friends a user has.
- I wanted to provide a technology that is as fast as relational data bases or flat files (due to denormalization) but still does not have redundnacy and can dynamically handle changes in the underlying network
How Graphity works is explained in my first presentation and my poster which I both already talked about in an older blog post. But you can also watch this presentation to get an idea of it and learn about the evaluation results:
Presentation at FOSDEM
I gave a presentation at FOSDEM 2012 in the graph Devroom which was video taped. Feel free to have a look at it. You can also find the slides from that talk at: http://www.rene-pickhardt.de/wp-content/uploads/2012/11/FOSDEMGraphity.pdf
Summary of results
in order to be among the first to receive the paper, the source code and the used data sets as soon as the paper is accepted sign in to my newsletter or follow me on twitter or subscribe to my rss feed.
With my data model graphity built on neo4j I am able to retrieve more than 10’000 dynamically generated news streams per second from the data base. Even in big data bases with several million users graphity is able to handle more than 100 newly created content items (e.g. status updates) per second which is still high if one considers that Twitter only had 600 tweets beeing created per second as of last year. This means that graphity is almost able to handle the amount of data that twitter needs to handle on a sigle machine! Graphity is creating streams dynamically so if the friendships of the network changes the user still get accurate news feeds!
Evaluation:
Although we used some data from metalcon to test graphity we realized that metalcon is a rather small data set. To overcome this issue we Used the german wikipedia as a data set. We interpreted every wikipedia article as a node in a social network. A link between articles as a follow relation and revisions of articles as status updates. With this in mind we did the following testings.
characteristics of the used data sets

As you can see the biggest data sets have 2 million users and 38 million status updates.

Nothing surprising here
STOU as a Baseline
Our baseline method STOU retrieves all the nodes from the egonetwork of an node and orders them by the time of their most recently created content item. Afterwards feeds are generated as in graphity by using top-k n-way merge algorithm.
7.2 Retrieving News Feeds
For every snapshot of the Wikipedia data set and the Metalcon data set we retrieved the news feeds for every aggregating node in the data set. We measured the time in order to calculate the rate of retrieved news feeds per second. With bigger data sets we discovered a drop in retrieval rate for STOU as well as GRAPHITY. A detailed analysis revealed that this was due to the fact that more than half of the aggregating nodes have a node degree of less than 10. This becomes visible when looking at the degree distribution. Retrieval of news feeds for those aggregating nodes showed that on average the news feed where shorter than our desired length of k = 15. Due to the fact that retrieval of smaller news feeds is significantly faster and a huge percentage of nodes having this small degree we conducted an experiment in which we just retrieved the feeds for nodes with a degree higher than 10.

We see that for the smallest data set GRAPHITY retrieves news feeds as fast as STOU. Then the retrieval speed for GRAPHITY rises and stays constant – in paticular independent of the size of the graph data base – as expected afterwards. The retrieval speed for STOU also stays constant which we did not expect. Therefor we conducted another evaluation to gain a deeper understanding.
Independence of the Node Degree
After binning articles together with the same node degree and creating bins of the same size by randomly selecting articles we retrieved the news feeds for each bin.

7.2.3 Dependency on k for news feeds retrieval
For our tests, we choose k = 15 for retrieving the news feeds. In this section, we argue for the choice of this value for k and show the influence of selecting k with respect to the performance of retrieving the news feeds per second. On the Wikipedia 2009 snapshot, we have retrieved the news feeds for all aggregating nodes with a node degree d > 10 and changed k.

Tthere is a clear dependency of GRAPHITY’s retrieval rate to the selected k. For small k’s, STOU’s retrieval rate is almost constant and sorting of ego networks (which is independent of k) is the dominant factor. With bigger k’s, STOU’s speed drops as both merging O(k log(k)) and sorting O(d log(d)) need to be conducted. The dashed line shows the interpolation of the measured frequency of retrieving the news feeds given the function 1/k log(k) while the dotted line is the interpolation based on the function 1/k. As we can see, the dotted line is a better approximation to the actually measured values. This indicates that our theoretical estimation for the retrieval complexity of k log(k) is quite high compared to the empirically measured value which is close to k.
Index Maintaining and Updating
Here we investigate the runtime of STOU and GRAPHITY in maintaining changes of the network as follow edges are added and removed as well as content nodes are created. We have evaluated this for the snapshots of Wikipedia from 2004 to 2008. For Metalcon this data was not available.
For every snapshot we simulated add / remove follow edges as well as create content nodes. We did this in the order as these events would occur in the wikipedia history dump.
handling new status updates

We see that the number of updates that the algorithms are able to handle drops as the data set grows. Their ratio stays however almost constant between a factor of 10 and 20. As the retrieval rate of GRAPHITY for big data sets stays with 12k retrieved news feeds per second the update rate of the biggest data set is only about 170 updated GRAPHITY indexes per second. For us this is ok since we designed graphity with the assumption in mind that retrieving news feeds happens much more frequently than creating new status updates.
handling changes in the social network graph

The ratio for adding follow edges is about the same as the one for adding new content nodes and updating GRAPHITY indexes. This makes perfect sense since both operations are linear in the node degree O(d) Over all STOU was expected to outperform GRAPHITY in this case since the complexity class of STOU for these tasks is O(1)

As we can see from the figure removing friendships has a ratio of about one meaning that this task is in GRAPHITY as fast as in STOU.
This is also as expected since the complexity class of this task is O(1) for both algorithms.
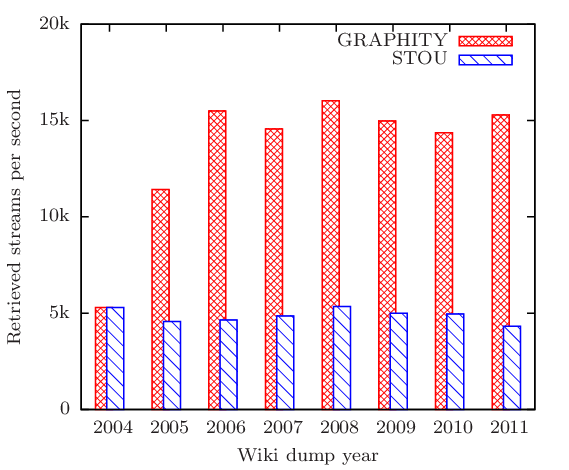
Build the index
We have analyzed how long it takes to build the GRAPHITY and STOU index for an entire network. Both indices have been computed on a graph with existing follow relations.
To compute the GRAPHITY and STOU indices, for every aggregating node $a$ all content nodes are inserted to the linked list C(a). Subsequently, only for the GRAPHITY index for every aggregating node $a$ the ego network is sorted by time in decending order. For both indices, we have measured the rates of processing the aggregating nodes per second as shown in the following graph.

As one can see, the time needed for computing the indices increases over time. This can be explained by the two steps of creating the indices: For the first step, the time needed for inserting content nodes increases as the average amount of content nodes per aggregating node grows over time. For the second step, the time for sorting increases as the size of the ego networks grow and the sorting part becomes more time consuming. Overall, we can say that for the largest Wikipedia data set from 2011, still a rate of indexing 433 nodes per second with GRAPHITY is possible. Creating the GRAPHITY index for the entire Wikipedia 2011 data set can be conducted in 77 minutes.
For computing the STOU index only, 42 minutes are needed.
Data sets:
The used data sets are available in another blog article
in order to be among the first to receive the paper as soon as the paper is accepted sign in to my newsletter or follow me on twitter or subscribe to my rss feed.
Source code:
the source code of the evaluation framework can be found at my blog post about graphity source. There is also the source code of the graphity server online.
in order to be among the first to receive the paper as soon as the paper is accepted sign in to my newsletter or follow me on twitter or subscribe to my rss feed.
Future work & Application:
The plan was actually to use these results in metalcon. But I am currently thinking to implement my solution to diaspora what do you think about that?
Thanks to
first of all many thanks go to my Co-Authors (Steffen Staab, Jonas Kunze, Thomas Gottron and Ansgar Scherp) But I also want to thank Mattias Persson and Peter Neubauer from neotechnology.com and to the community on the neo4j mailinglist for helpful advices on their technology and for providing a neo4j fork that was able to store that many different relationship types.
Thanks to Knut Schumach for coming up with the name GRAPHITY and Matthias Thimm for helpful discussions